亚马逊AI复苏:AWS与Anthropic的多吉瓦特Trainium扩展
两年半前,我们指出了AWS即将面临的”云计算危机”。如今,证据已经累积。AWS是亚马逊帝国的皇冠明珠,贡献了约60%的集团利润,并在利润丰厚的云计算市场占据主导地位。但它难以将这一优势转化为新的GPU/XPU云计算时代。
微软Azure现在在季度新增云收入方面领先市场,谷歌云与AWS之间的差距也显著缩小,特别是随着我们过去一个多月一直在报道的谷歌在TPU方面的大动作。市场已经注意到。年初至今,在四大科技和AI巨头中,亚马逊明显落后,投资者因亚马逊在AI领域失去势头而大幅下调了该公司评级。
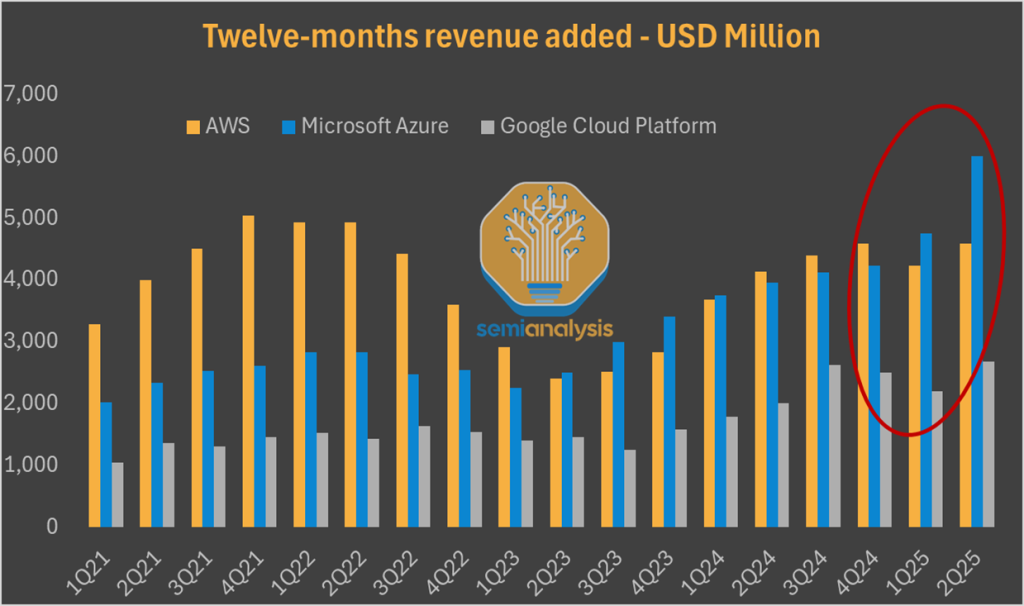
今天,SemiAnalysis带来了另一个超出预期的观点。虽然市场过度渲染了”云计算危机”的主题,但我们预测AWS将迎来AI复苏。一个月前,我们向我们的核心研究订阅者阐述了这一论点,预测到2025年底,AWS将实现超过20%的同比增长率。
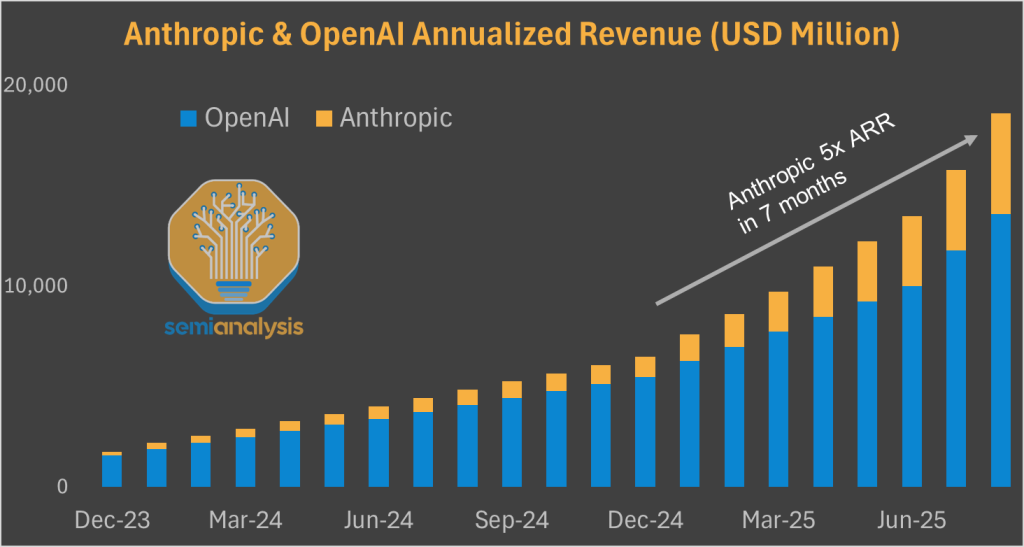
亚马逊的救世主有一个名字:Anthropic。这家初创公司在2025年生成式AI市场中表现突出,收入同比增长五倍,达到50亿美元的年化收入。
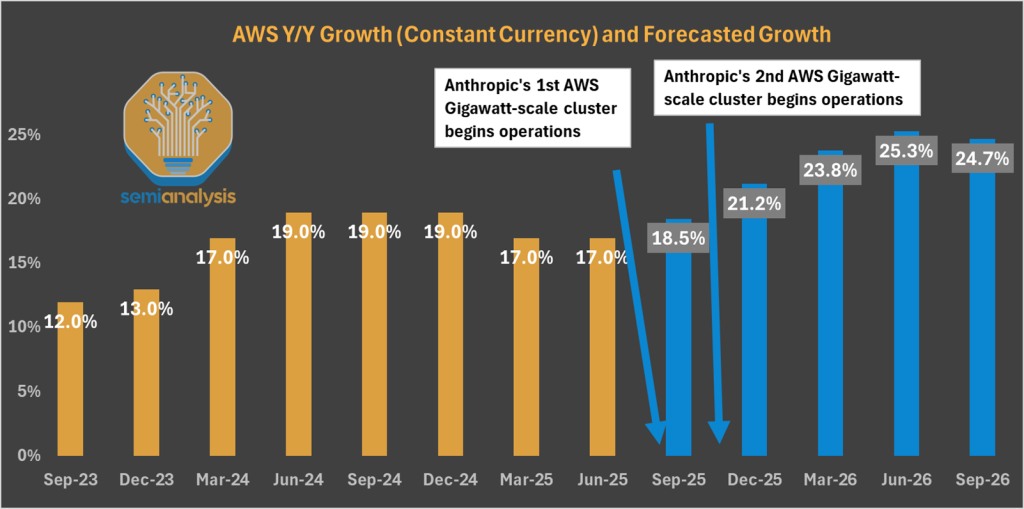
为了保持这一增长轨迹,Anthropic正全力投入扩展法则。尽管Dario的初创公司获得的头条新闻少于OpenAI、xAI和Meta超级智能,但它并不 shy于投资。AWS为其主要客户建设的数据中心容量已超过1吉瓦,处于最终建设阶段。AWS的数据中心建设速度比其历史上任何时候都快。而且未来还有更多计划。
要了解和预测按AI实验室划分的GPU/XPU电力容量,我们依靠我们专有的数据中心行业模型,该模型由实时卫星图像提供支持。所有超大规模云服务商、AI实验室和世界最大投资者都信任该模型,它为OpenAI、Anthropic、xAI、Meta超级智能、Google DeepMind等提供按季度、按建筑的数据中心预测。
Trainium与GPU对比
虽然亚马逊的AI数据中心在规模和速度上令人印象深刻,但单个建筑设计并不突出。针对空气冷却进行了优化,这一蓝图与5年前的传统AWS云数据中心相同。
使这些设施独特的是其内部:它们将托管世界上最大的非Nvidia AI芯片集群,最大校区将部署近百万个Trainium2芯片。要全面了解Trainium2系统,请阅读我们2024年12月的技术深度分析。

Trainium2在许多方面落后于Nvidia的系统,但它对多吉瓦特AWS/Anthropic交易至关重要。其每TCO内存带宽优势完美契合Anthropic的强化学习路线图。Dario的初创公司深度参与了设计过程,其对Trainium路线图的影响只会越来越大。
简单地说:Trainium2正在向Anthropic定制硅计划发展。这将使Anthropic与Google DeepMind一起,成为近期内唯一受益于紧密的硬件-软件协同设计的AI实验室。
AWS GenAI表现不佳
要理解亚马逊在生成式AI时代表现不佳的原因,我们可以分析GPU/XPU云市场成功的驱动因素。最简单的方式是,我们看到GPU/XPU容量的两个主要客户群体:
- 批量裸机用户:如OpenAI、Anthropic、字节跳动等超大规模客户。
- 托管SLURM/Kubernetes:如初创公司、研究机构和试点项目等较小客户。
云计算危机和ClusterMAX表现不佳
在第二类客户中,我们的ClusterMAX AI云评级是比较相对优势和劣势的最佳方式。铂金级和黄金级AI云比其他云获得了更多关注,并且拥有高于平均水平的定价能力。因此,CoreWeave、Oracle、Nebius、Crusoe和Azure等多租户GPU集群市场表现优于市场——这些集群需要高性能和先进的软件层。

正如两年前所预测的,亚马逊表现不佳的关键在于使用自定义网络 fabric EFA。AWS在前端网络上的ENA成功尚未转化为后端的EFA。EFA在性能上仍落后于其他网络选项:Nvidia的InfiniBand和Spectrum-X,以及思科、Arista和Juniper的RoCEv2选项。原始性能不是唯一指标,EFA的用户体验也不如InfiniBand和RoCEv2。也就是说,随着亚马逊最新的EFAv4在实际消息大小上的性能改进,尽管仍落后于竞争对手。
亚马逊的自定义网络还减少了其上市时间,因为需要定制Nvidia系统。其他项目如先进的被动和主动自动化每周计划健康检查策略也不如黄金和铂金级云稳固。
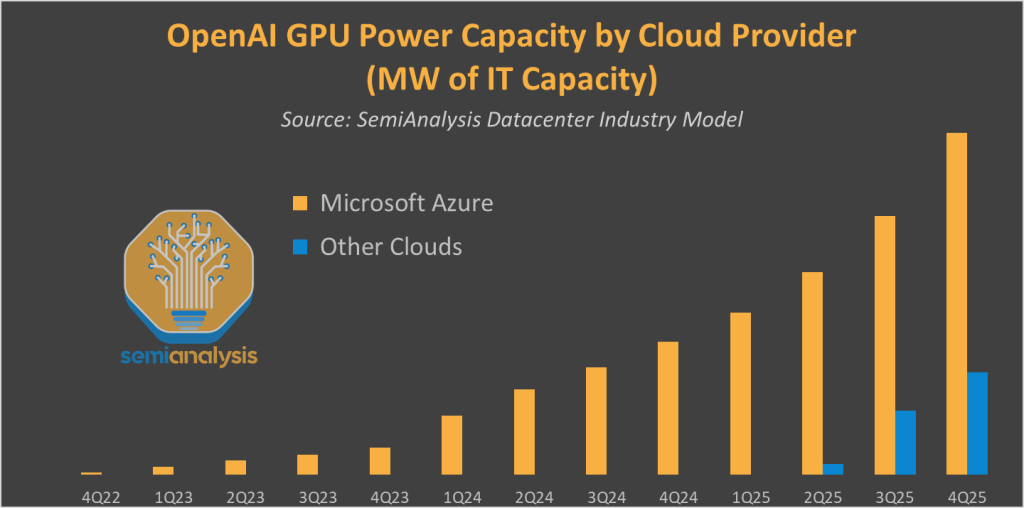
寻找锚定客户
对AWS XPU业务增长更重要的是能够锁定锚定客户——这是第一波生成式AI需求的市场创造者。规模、上市时间、深度合作和定价是赢得这些账户的关键,比先进的软件层更重要。
没有哪家公司能比微软更好地说明这一点。Azure在AI方面超越同行的表现完全归功于其与OpenAI的合作。截至2025年第二季度(6月),OpenAI所有超过100亿美元的云支出都由Azure预订。
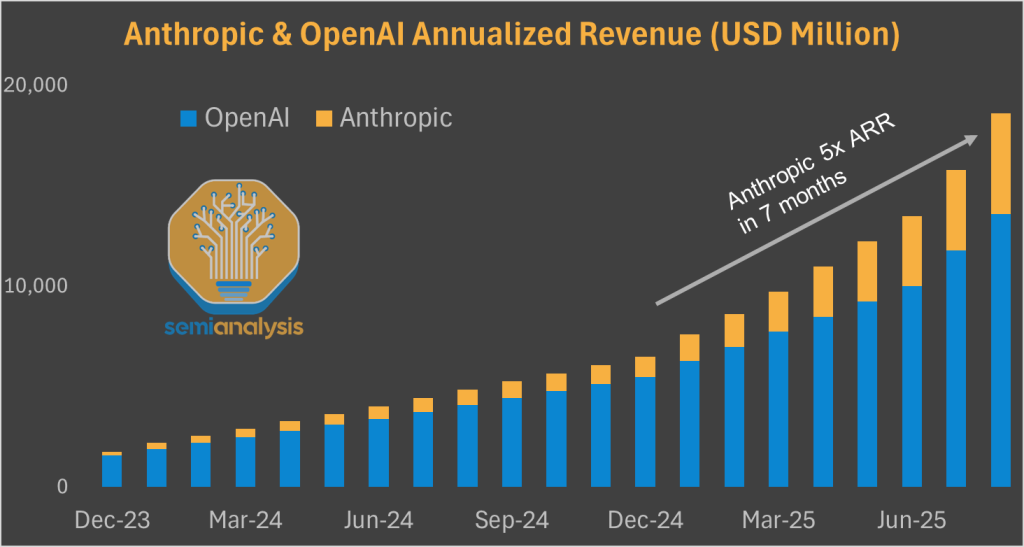
亚马逊很早就理解了锚定客户的重要性,并于2023年9月向Anthropic投资12.5亿美元(可扩展至40亿美元)。该合作在2024年3月扩大,Anthropic承诺使用Trainium和Inferentia芯片。2024年11月,亚马逊向Anthropic额外投资40亿美元,后者将AWS命名为其主要LLM训练合作伙伴。
Anthropic的出色表现与AWS的疲软
亚马逊的赌注是正确的。Anthropic在2025年生成式AI市场中表现突出,收入从10亿美元飙升至50亿美元的年化收入。在这种情况下,AWS的表现不佳令投资者沮丧,但他们误解了Anthropic在训练和推理方面的支出构成。
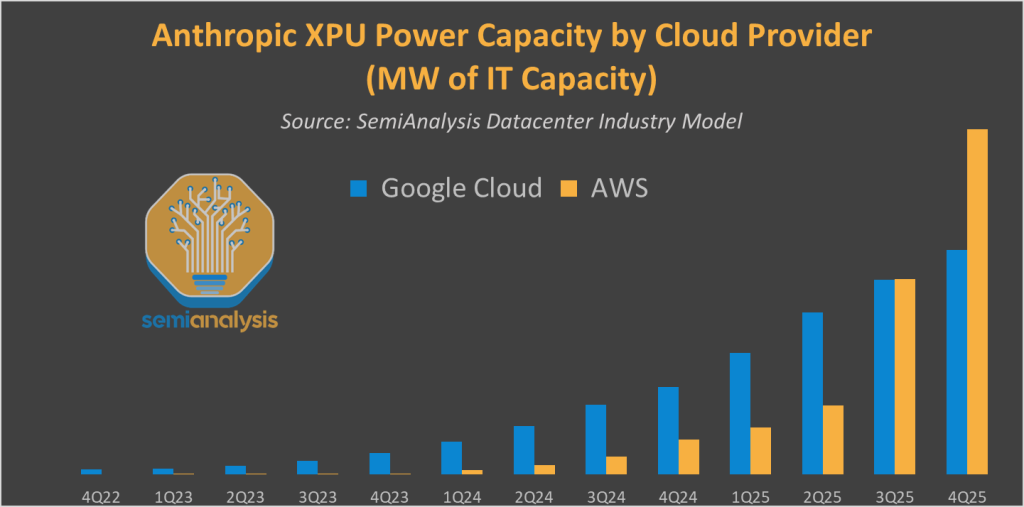
有两个明确的解释为什么亚马逊尚未真正从与Anthropic的关系中受益:

- 截至2025年第二季度,Anthropic的云支出比OpenAI小2倍以上。
- Anthropic的大量支出流向了谷歌云——Anthropic最早的 major 投资者之一(2022年底3亿美元轮)以及在扩展的AWS协议之前的2023年和2024年的首选云合作伙伴。
Anthropic与AWS多吉瓦特AI训练基础设施
特别是,我们相信Anthropic的大部分推理需求由谷歌云满足。拥有世界上最好的推理系统(TPU)是关键竞争优势。
AWS基础设施建设的目的是为了服务其主要客户的训练需求。虽然Anthropic获得的头条新闻不如OpenAI、xAI和Meta等同行,但它完全投入了AGI竞赛,并计划在训练支出上毫不吝啬。Anthropic领导层真正相信扩展强化学习。
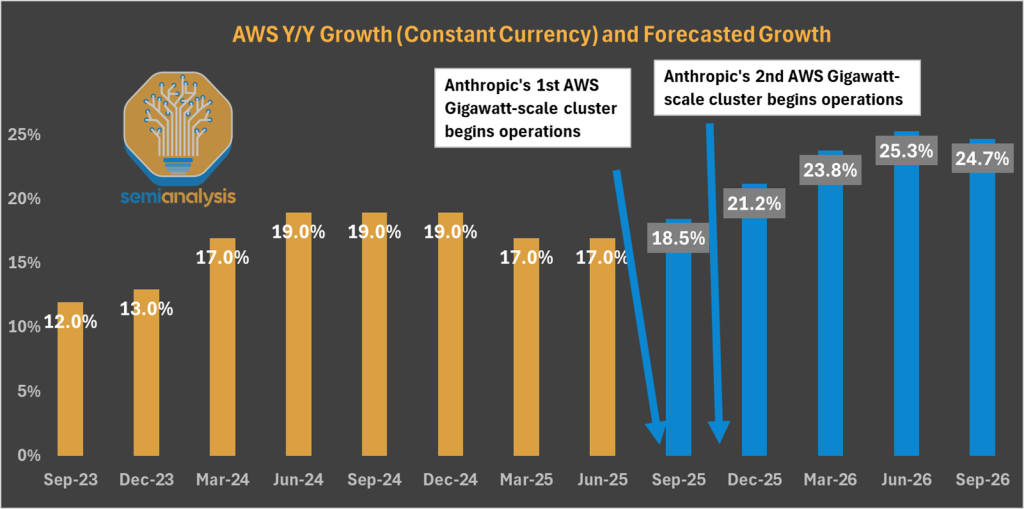
他们的信念将在今年内实现。我们在下面展示了三个处于最终建设阶段的AWS校区,拥有超过1.3吉瓦的IT容量,专门用于服务Anthropic的训练需求。建设速度令人瞩目。
Anthropic并未止步于此。其130亿美元的融资轮(183亿美元估值)将提供资金,与AWS、谷歌等签署额外协议。AWS并非坐等——他们已经开始建设吉瓦规模的新数据中心,以捕捉这一增长。

如前所述,这些数据中心将主要填充AWS的自定义芯片Trainium。鉴于其规模,我们无法低估Anthropic的赌注有多大。他们不仅承诺花费数百亿美元,而且是在一个 largely 未经证实的芯片上!
Trainium2 TCO分析——Anthropic的大赌注如何获得回报
Trainium2供应链信号目前非常强劲。我们行业领先的AI加速器模型跟踪封装运输和系统/机架运输,自年初以来它们大幅增长。它为构成Trainium2和Trainium3产品系列的10多个SKU提供季度数量预测,并指出将 disproportionate 受益于特定SKU的供应商。
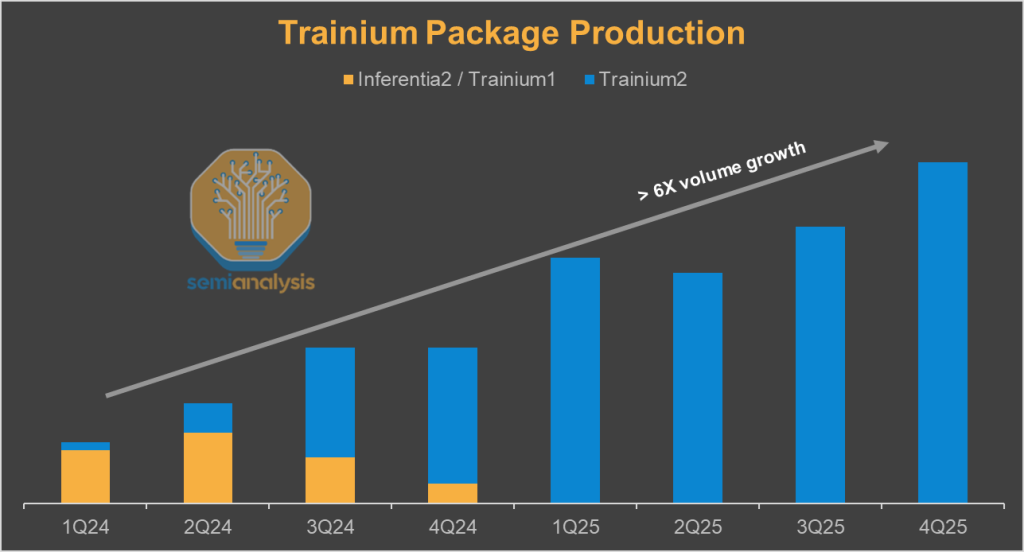
与Nvidia和谷歌的TPU竞争当然不是小事。虽然谷歌正在推出其第七代TPU Ironwood,但Trainium2只是亚马逊的第三代AI加速器。
芯片规格:Trainium2在各方面都落后,但是…
简单的芯片规格显示,Trainium相对于Nvidia明显落后:
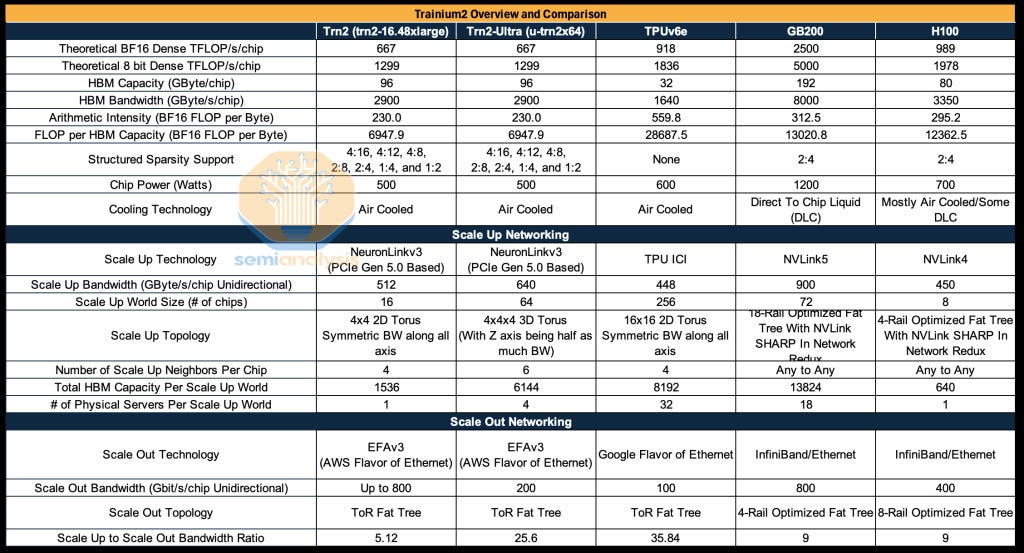
- Nvidia的GB200在FP16 FLOPs方面有3.85倍优势,每芯片2500 TFLOP/s,而Trainium2为667 TFLOP/s/芯片。请注意,规格表数字相比实际可实现的FLOPs有所夸大。
- 在内存带宽方面,差距缩小到2.75倍,8000GB/s/GPU对2900GB/s/Trn2
在评估扩展网络带宽时是另一个关键项目。我们已经多次解释了扩展网络对推理模型推理的重要性。我们对强化学习的深入探讨强调了RL与推理工作负载的相似性,使内存带宽成为训练后扩展的关键项目。
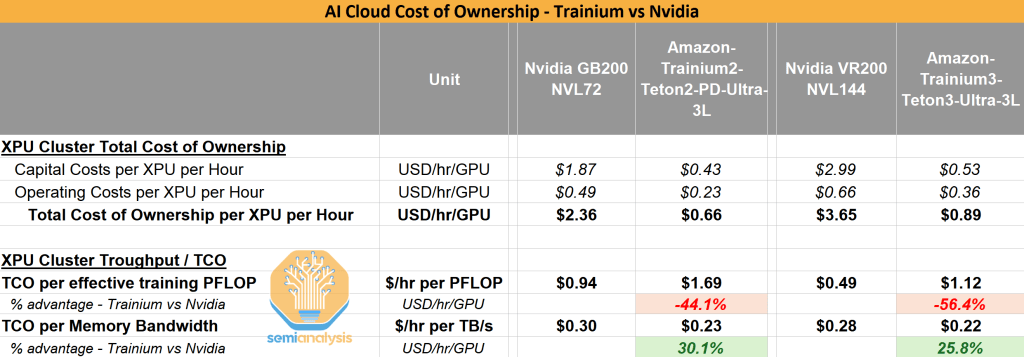
虽然Trainium明显落后,但一旦我们考虑总拥有成本(TCO),情况就会改变。
Trainium的每TCO内存带宽优势
在下表中,我们将TCO纳入比较。虽然Nvidia在每有效训练PFLOP的TCO方面有显著优势,但Trainium2在每百万token的TCO和每TB/s内存带宽的TCO方面极具竞争力。
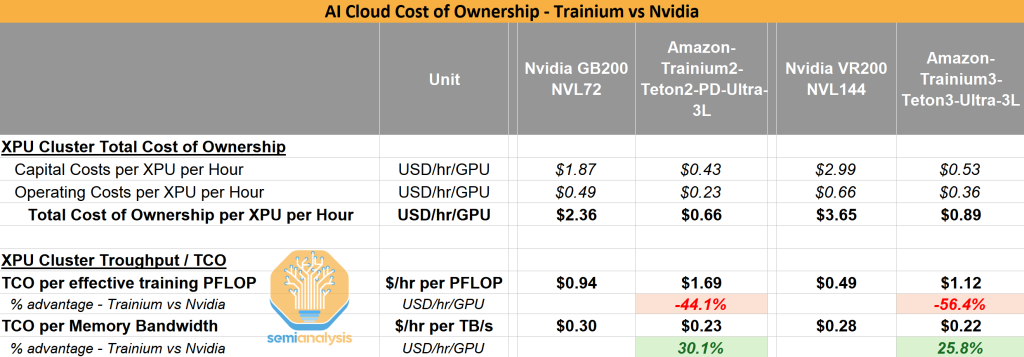
Trainium2的每TCO内存带宽优势是理解Anthropic选择的关键。虽然Nvidia的芯片和系统在大多数方面都更好,但Trainium2完美契合Anthropic的路线图。他们是最激进的AI实验室,专注于扩展训练后技术如强化学习。他们的路线图更多受内存带宽限制而非FLOPs限制。我们最近的HBM报告深入解释了哪些AI工作负载倾向于内存受限。
Trainium的路线图:加倍投入系统
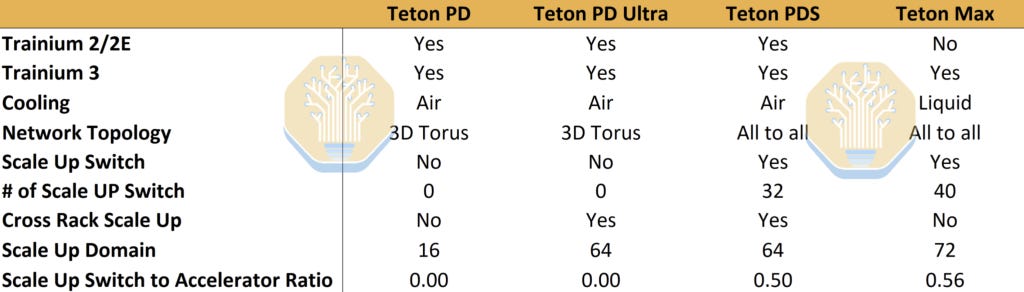
亚马逊正在为其主要客户推出新的系统级架构。目前,AWS部署的两个系统是Teton PD和Teton PD Ultra。明年,新的Teton PDS和Teton Max将大量出货。
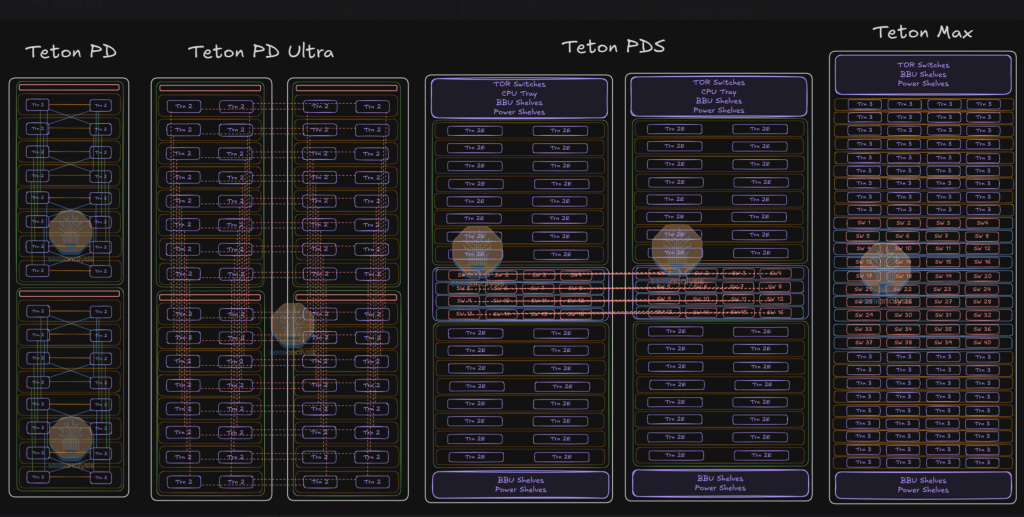
关键区别是引入了一个名为NeuronLinkv3的全对全扩展网络。因此,Trainium的架构正在向Nvidia的NVL72 NVLink发展。
四个NeuronLinkv3交换机托盘将放置在机架中间,上方和下方各有16个计算托盘均匀分布。某些供应链供应商将 disproportionate 受益,正如两个月前在核心研究中所强调的那样——我们的机构研究服务受到世界上最大对冲基金的信任。该供应商自我们发布以来上涨了73%。我们认为PDS的引入是Trainium追赶Nvidia的中间步骤。我们还相信Anthropic在新系统级架构的推出中发挥了重要作用。

不会的,打雷了要下雨了