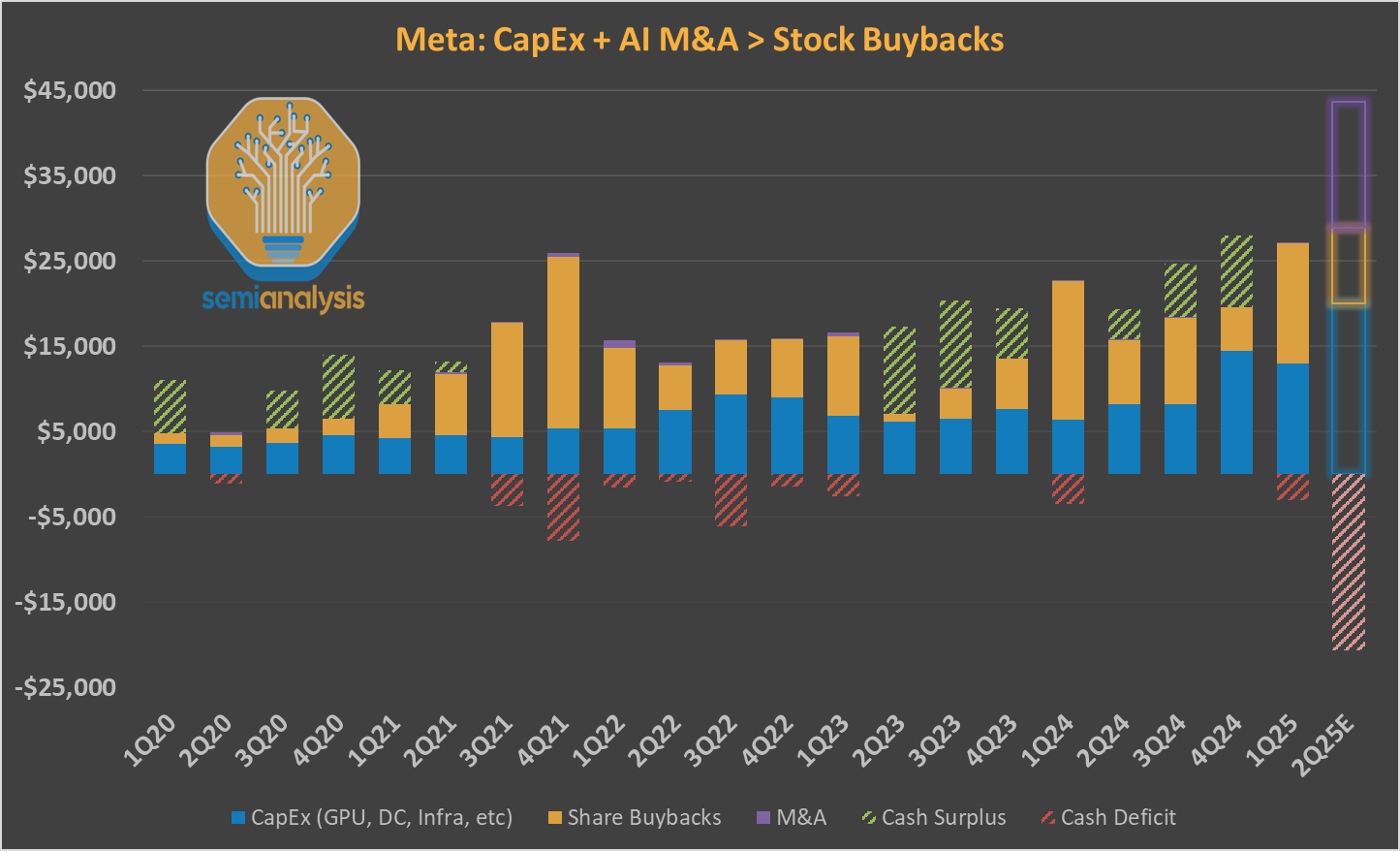
Meta以约300亿美元估值收购Scale AI 49%的股份,这表明这个拥有1000亿美元年现金流的广告机器对资金毫不吝啬。尽管似乎拥有无限资源,但Meta在模型性能方面一直落后于基础实验室。
真正的警醒信号是Meta在开源模型领域失去了领先地位,输给了DeepSeek。这唤醒了这只沉睡的巨人。如今,Mark Zuckerberg完全以创始人模式亲自领导Meta的AI战略,指出了Meta的两个核心短板:人才和计算能力。作为少数仍掌管科技巨头的创始人之一,Mark不需要SemiAnalysis来提醒他放缓股票回购以投资未来!
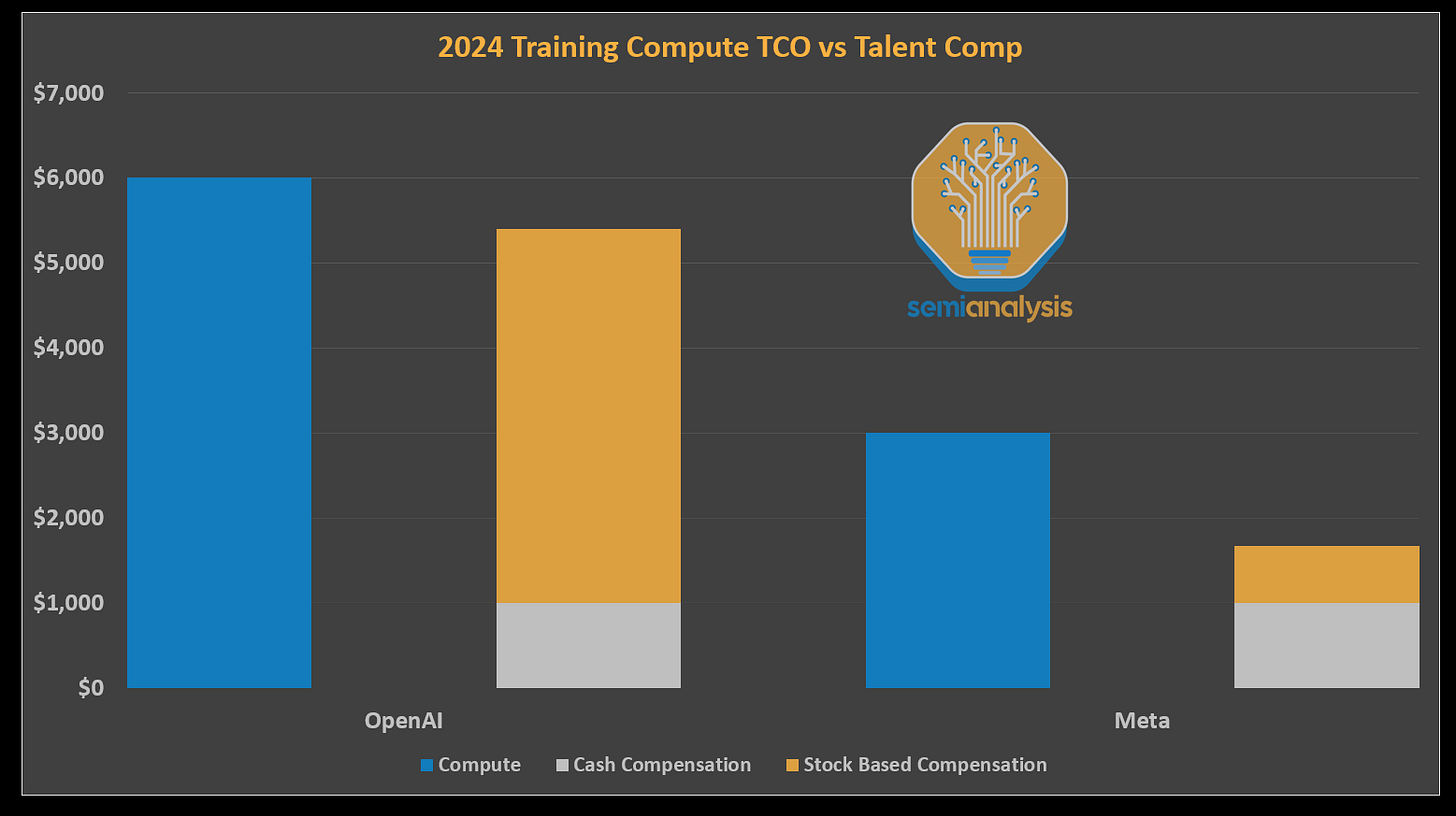
除了投入资金解决问题外,Zuckerberg从根本上重新思考了Meta在生成式AI方面的方法。他正在从零开始组建一个新的”超级智能”团队,并以高薪亲自招募顶尖AI人才,其薪酬之高使顶级运动员的薪水看起来微不足道。被招募到这个团队的典型报价是4年2亿美元,这是他们同行薪酬的100倍。此外,Meta还向OpenAI的研究/工程领导层提供了价值数十亿美元的报价,但未获接受。虽然这些报价并非全部成功,但Zuckerberg通过大幅提高员工的成本,正在严重打击竞争对手。
同样引人注目的是,Zuckerberg将整个数据中心策略扔进了垃圾桶,现在正在”帐篷”中建造价值数十亿美元的GPU集群!

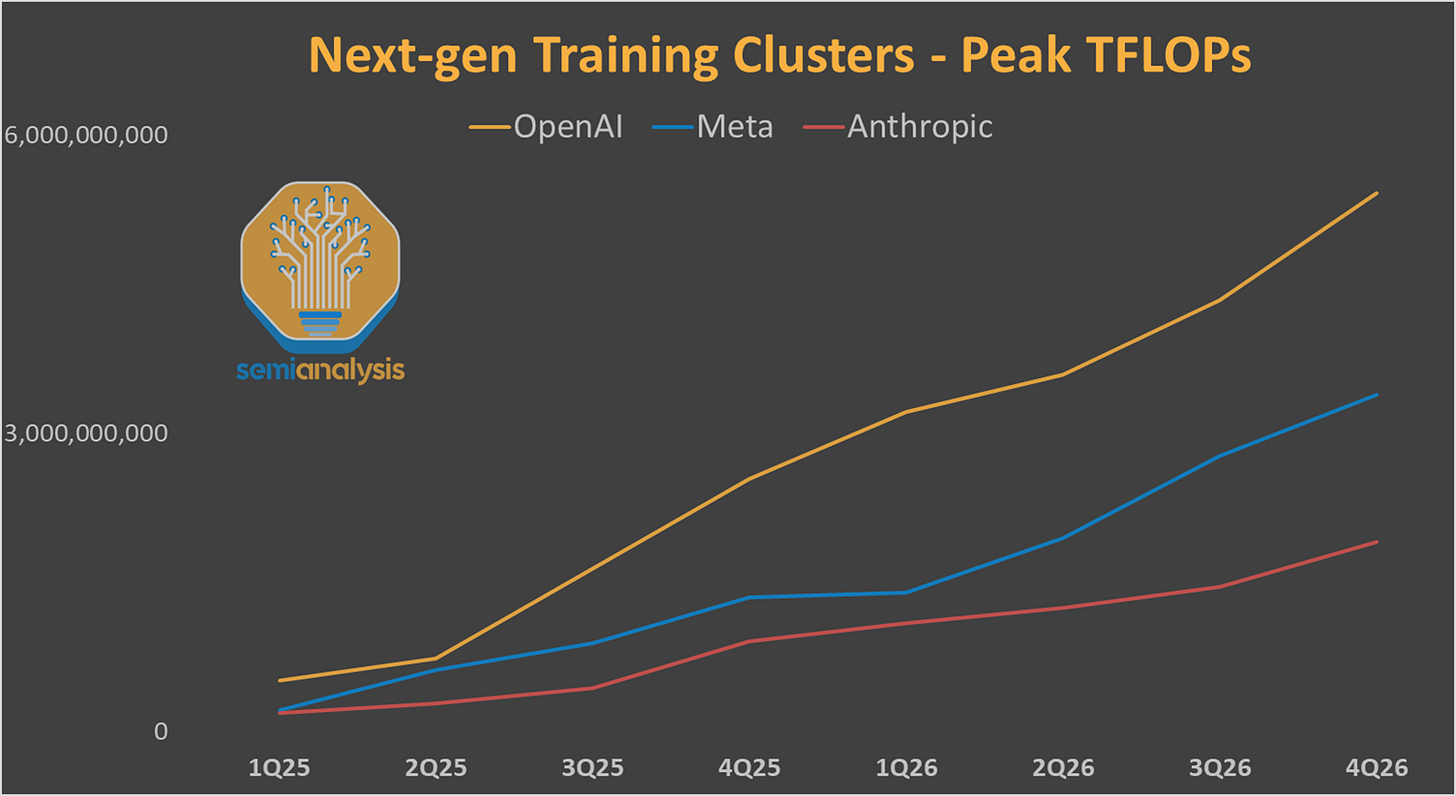
正如本报告详细阐述的,Meta在追求超级智能的过程中,正在从计算能力到人才进行前所未有的变革。从Llama 3.0开源模型的统治地位到Llama 4 Behemoth的史诗性失败,这个AI巨头虽然暂时受挫但并未出局。事实上,我们相信Meta在训练FLOPS方面的增长速度甚至可能超过OpenAI。这家公司正在从每个研究人员缺乏GPU转变为拥有极其丰富的GPU资源。
Meta GenAI 1.0:AI渐进主义
与OpenAI等纯AI实验室相比,Meta和Google等公司遵循”AI渐进主义”战略,通过改进推荐系统和生成式AI来增强现有产品,以改善广告定向、内容标记和内部工具。这已在财务成果上获得丰厚回报,使Meta能够摆脱苹果在iOS 14.5(2021年末至2022年初)发布应用跟踪透明度(ATT)功能后阻止其跟踪用户的尝试。
虽然Meta可能比Google更能抵御生成式AI的颠覆,但两家公司的LLM努力都有些令人失望。一个原因是资本主要分配给核心业务,而不是追求超级智能。
“我们今年的资本支出增长将同时用于生成式AI和核心业务需求,其中大部分总体资本支出支持核心业务。”
来源:Meta 2025年第一季度财报电话会议,SemiAnalysis强调
对于这些科技巨头来说,生成式AI是其业务的延伸。它们不像OpenAI在聊天机器人或Anthropic在编码API方面那样有主导新用例的生存需求。这在OpenAI等领先AI基础实验室与Meta之间的计算能力与人力资本分配中表现得非常明显。Zuckerberg对竞争性报价的影响和薪资膨胀将造成严重伤害。
因此,在衡量生成式AI消费者应用的吸引力时,Meta和Google在覆盖面和参与度方面明显落后于ChatGPT。
但情况正在改变。利用我们专有的加速器行业模型和数据中心行业模型,我们预测Meta在未来几年将在生成式AI投资方面实现显著提升。
Meta GenAI 2.0 – 第一部分:重新发明数据中心策略(再次)
从建筑到帐篷
就在一年前,Meta放弃了其十年之久的”H”形数据中心蓝图,转而采用新的AI优化设计。
现在在2025年,Zuckerberg决定再次重新设计策略。受xAI前所未有的上市速度启发,Meta正在采用一种优先考虑速度的数据中心设计。他们已经在建造更多这样的数据中心!传统的数据中心和房地产投资者仍然对xAI的孟菲斯站点和上市速度感到震惊,现在将再次受到震撼。
这种设计不是为了美观或冗余,而是为了快速计算上线!从预制电源和冷却模块到超轻结构,速度至关重要,因为没有备用发电(即没有柴油发电机)。
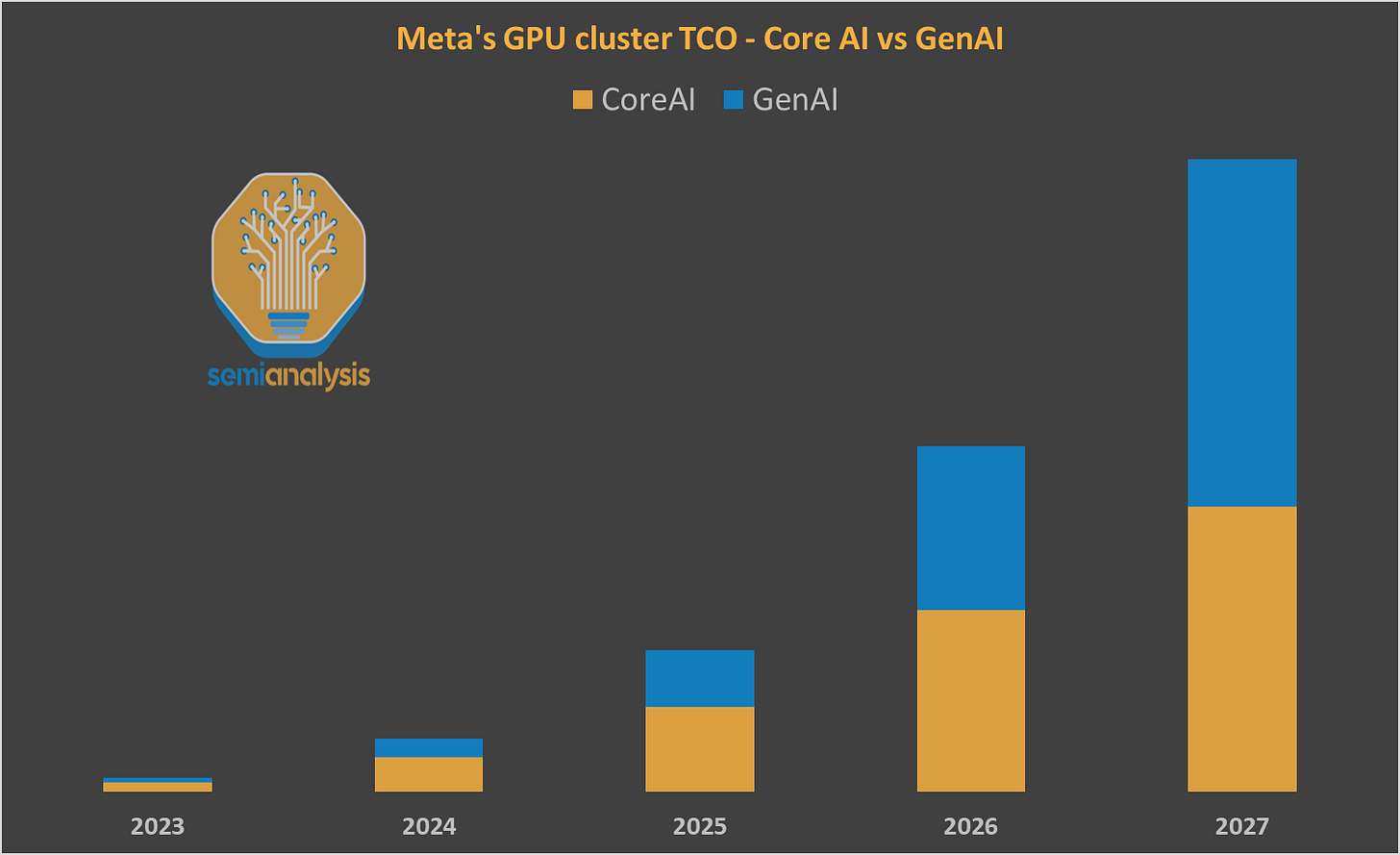
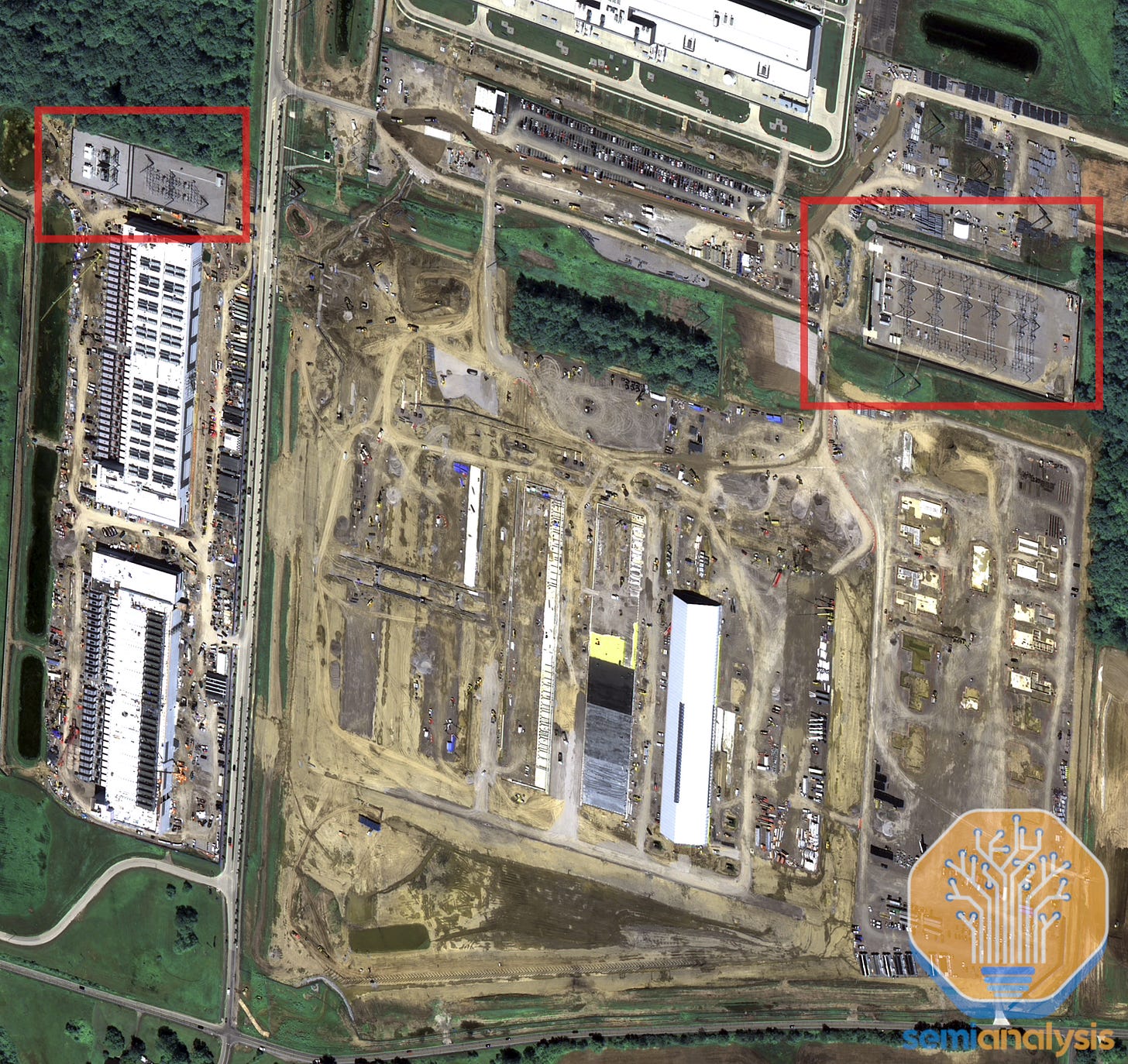
目前使用附近的Meta现场变电站。Meta可能使用复杂的工作负载管理来最大化从电网获得的每一瓦电力的利用率。在最热的夏天,它甚至可能需要关闭工作负载。
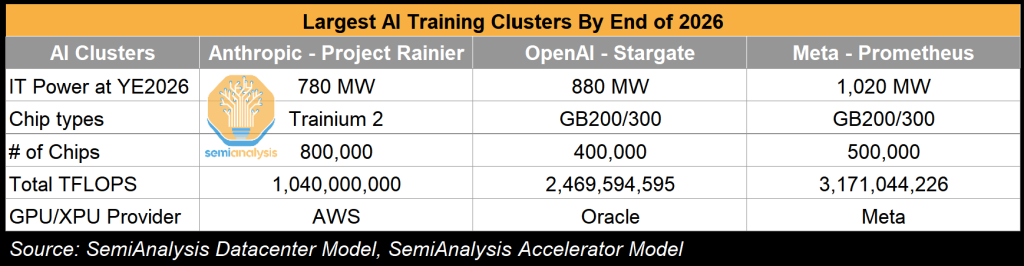
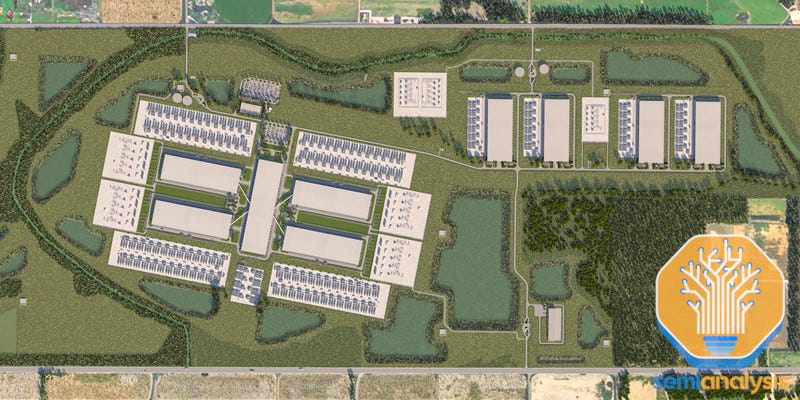
Prometheus 1GW AI训练集群——”全方位”基础设施战略
Meta正在俄亥俄州悄悄建设世界上最大的AI训练集群之一。我们从其基础设施组织内部人士获悉,他们称这个集群为Prometheus。为了击败竞争对手AI实验室,Meta实施了”全方位”基础设施战略:
- 自建校园
- 从第三方租赁
- AI优化设计
- 多数据中心校园训练
- 现场、计量后的天然气发电
展望下方的Prometheus训练集群,我们相信Meta正在使用超高速网络连接所有这些站点,所有这些都由Arista 7808交换机通过Broadcom Jericho和Ramon ASIC提供支持的后端网络。

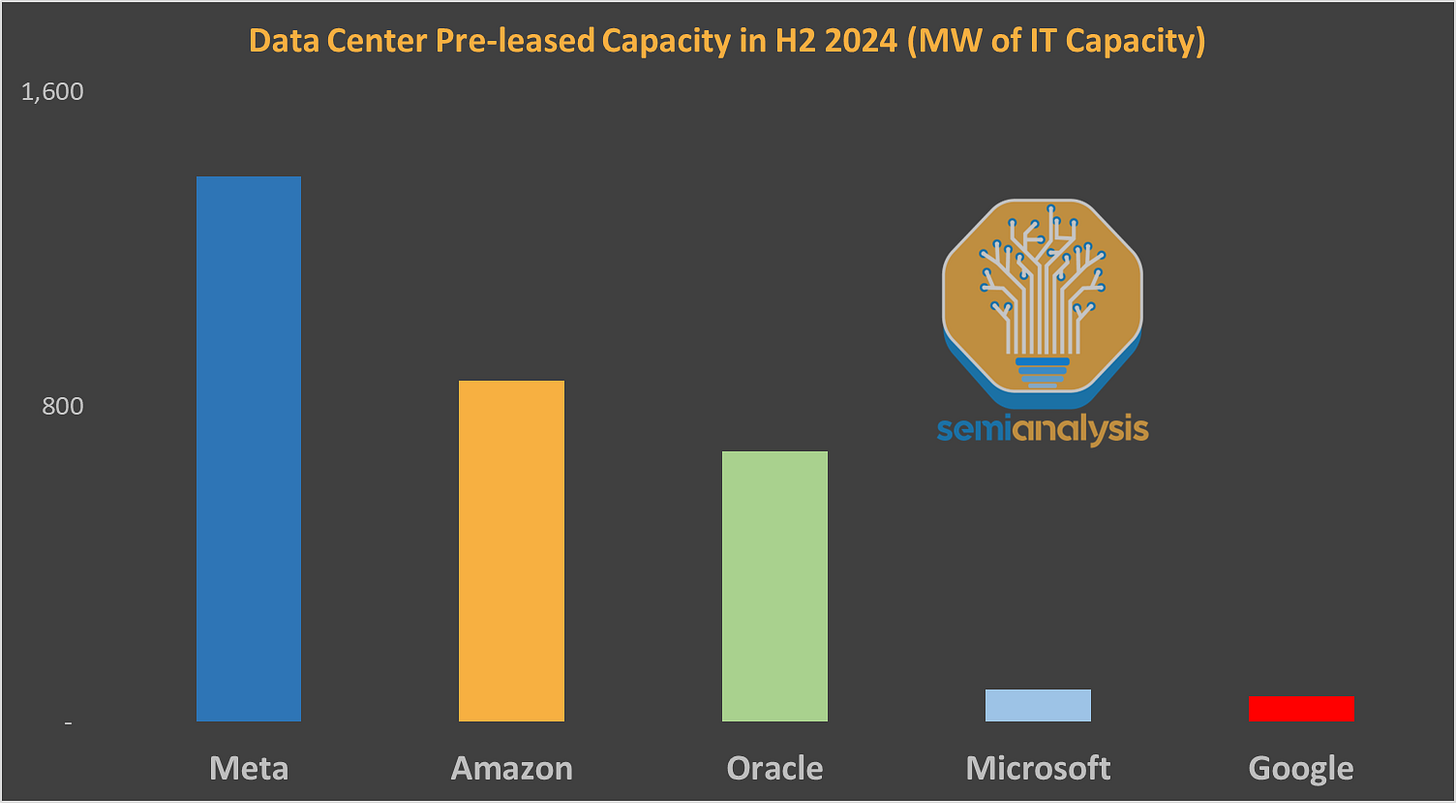
通过结合自建和租赁,Meta能够更快地扩展。事实上,他们在2024年下半年预租用的容量超过了任何超大规模企业,主要在俄亥俄州。
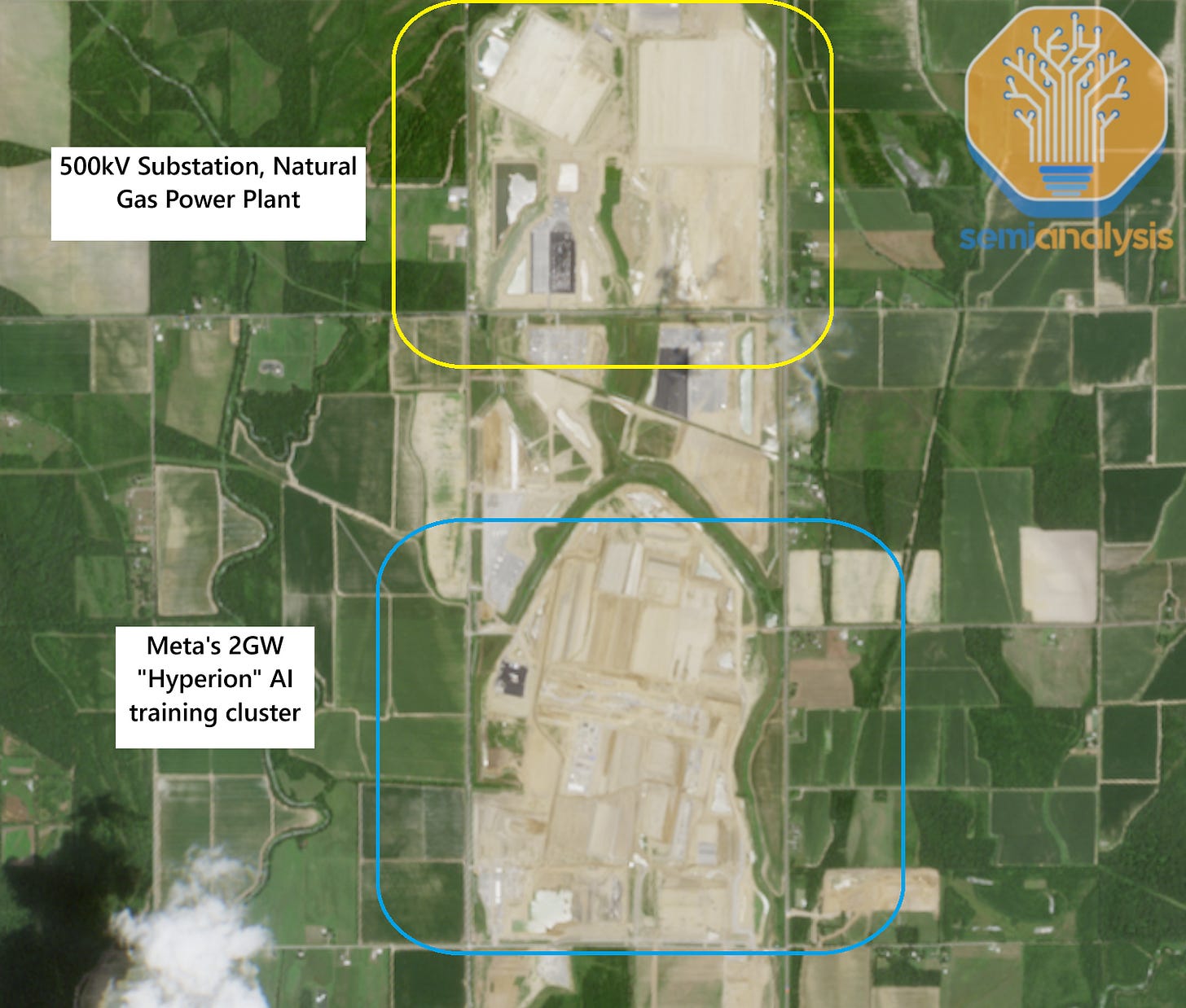
此外,当当地电网无法满足需求时,Meta采用了完全的埃隆模式。在Williams的帮助下,他们正在建造两座200MW现场天然气发电厂。第一个设备的分解包括:

- 3台Solar Turbines的Titan 250涡轮机
- 9台PGM 130涡轮机
- 3台Siemens Energy SGT400涡轮机
- 15台CAT 3520往复式发动机
OpenAI的这种计算优势很重要,因为强化学习的出现意味着美国各地的许多大型数据中心可以异步使用,通过训练后来改进模型智能。
不甘示弱,Meta的第二个前沿集群Hyperion旨在消除与OpenAI的差距。
在规模上超越星门:Meta的Hyperion 2GW集群
虽然所有目光都集中在Abilene的高调星门数据中心上,但Meta已经计划了超过一年的应对措施并取得了巨大进展。路易斯安那州集群预计将在2027年底成为全球最大的单个校园,第一阶段IT功率超过1.5GW。内部人士告诉我们,这内部命名为Hyperion。
Meta在2024年底破土动工,目前正在积极建设电力基础设施和数据中心校园。
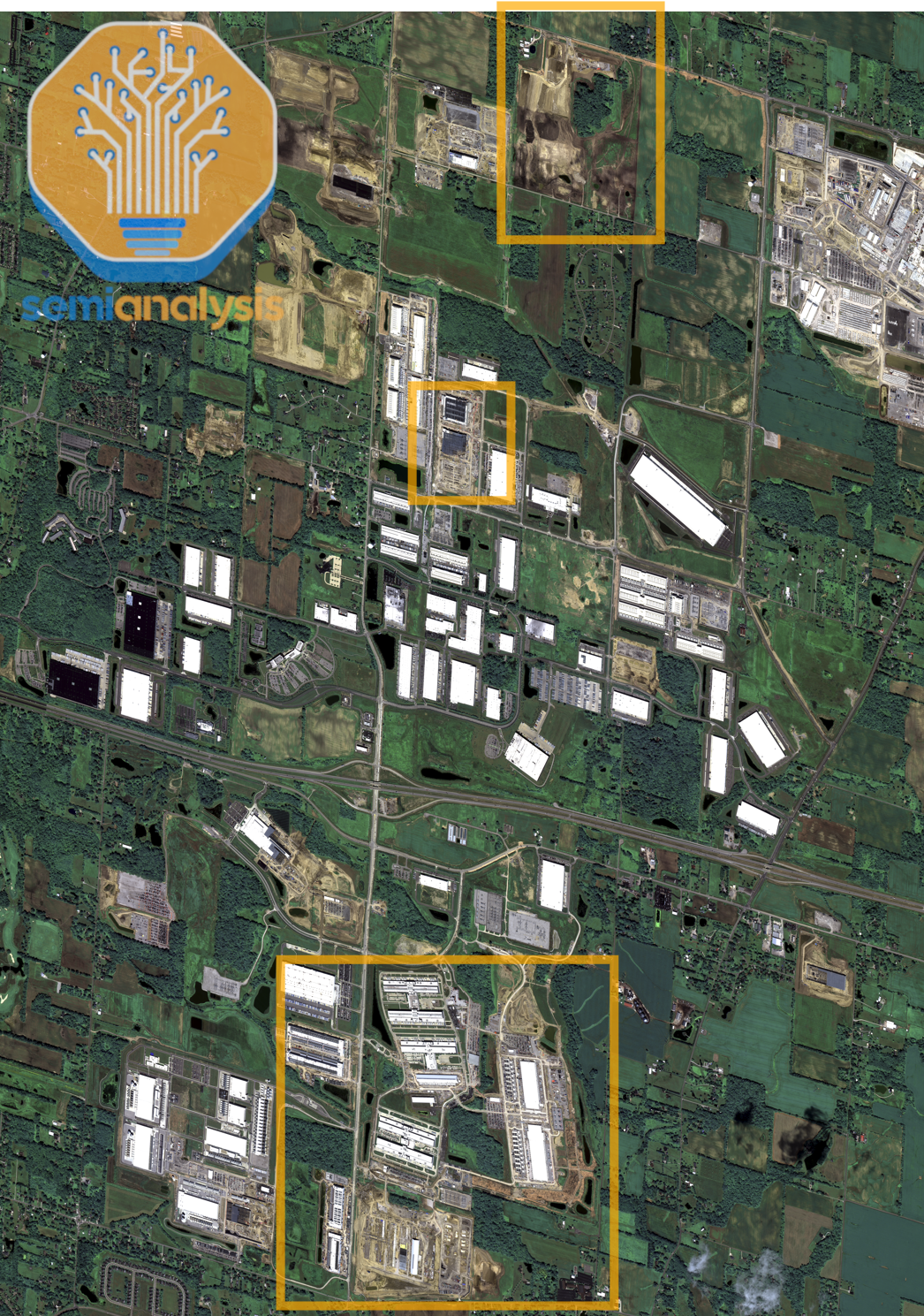
需要明确的是,Meta还有许多其他数据中心正在建设和扩展。Meta的所有AI数据中心、预计完成日期和每季度每栋建筑的全部电力列表,可以在我们的数据中心行业模型中找到。
Llama 4失败——从开源王子到巨人的乞丐
在我们深入研究超级智能人才竞赛之前,我们应该看看Meta是如何陷入这种尴尬处境的。在Llama 3引领开源前沿后,Meta发现自己现在落后于中国的DeepSeek。
在技术层面,我们认为失败的主要原因如下:
- 分块注意力
- 专家选择路由
- 预训练数据质量
- 扩展策略和协调
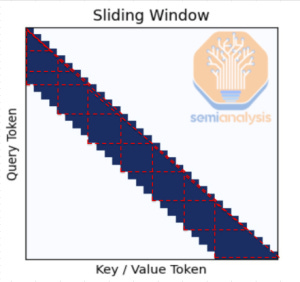
分块注意力
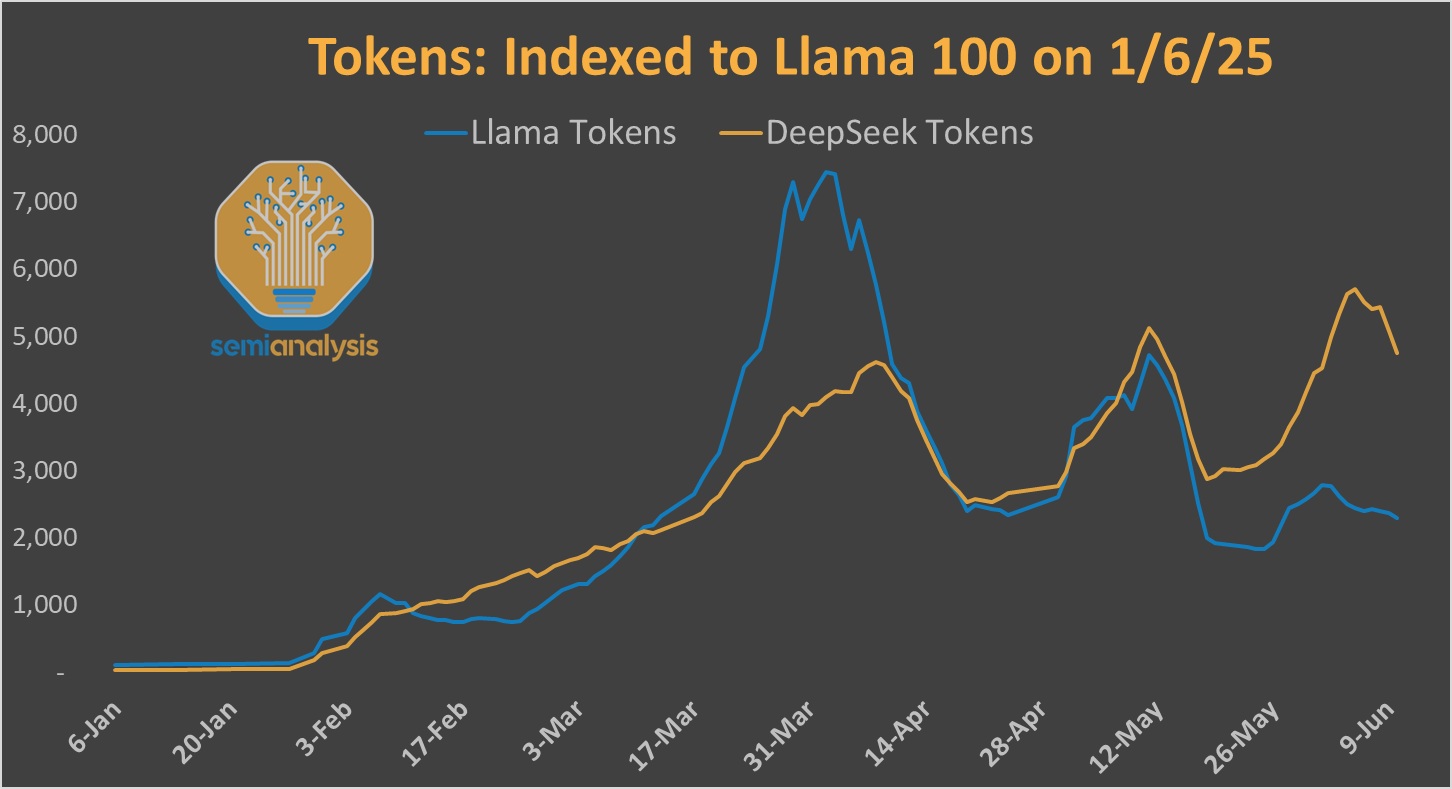
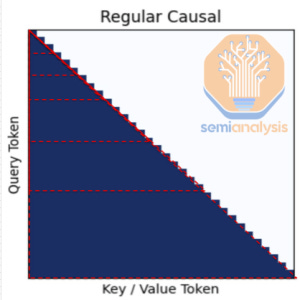
天真实现时,大型语言模型中的注意力机制与标记数量呈二次方扩展。为了解决这个问题,研究人员引入了内存高效的机制。Meta为Behemoth选择了分块注意力,这可能是一个错误。
标准因果注意力:想象一系列从左上角展开的三角形,代表每个后续标记的注意力大小。标记数量翻倍,三角形的面积增加四倍。

分块注意力将这个三角形分解为固定大小的块。每个块将注意力重置为新的”第一个”标记。在内存效率提高的同时,它甚至可以实现更长的上下文。Meta认为他们需要这一点来实现长上下文,但权衡得不偿失。每个块中的第一个标记无法访问之前的上下文。虽然有一些全局注意力层,但这还不够,正如我们下面将详细讨论的。
滑动窗口注意力是其他模型使用的更平滑的替代方案:注意力窗口逐个标记向前滑动。这保持了局部连续性,即使长程推理仍然需要多层来传播上下文。
Behemoth对分块注意力的实现追求效率,创造了盲点,特别是在块边界处。这影响了模型发展推理能力的能力,因为思维链的长度超过一个块。模型难以进行长程推理。虽然这在事后看来似乎很明显,但我们认为部分问题是Meta甚至没有适当的长上下文评估或测试基础设施来确定分块注意力对开发推理模型不起作用。Meta在强化学习和内部评估方面非常落后,但新招募的员工将大大缩小推理差距。
专家选择路由
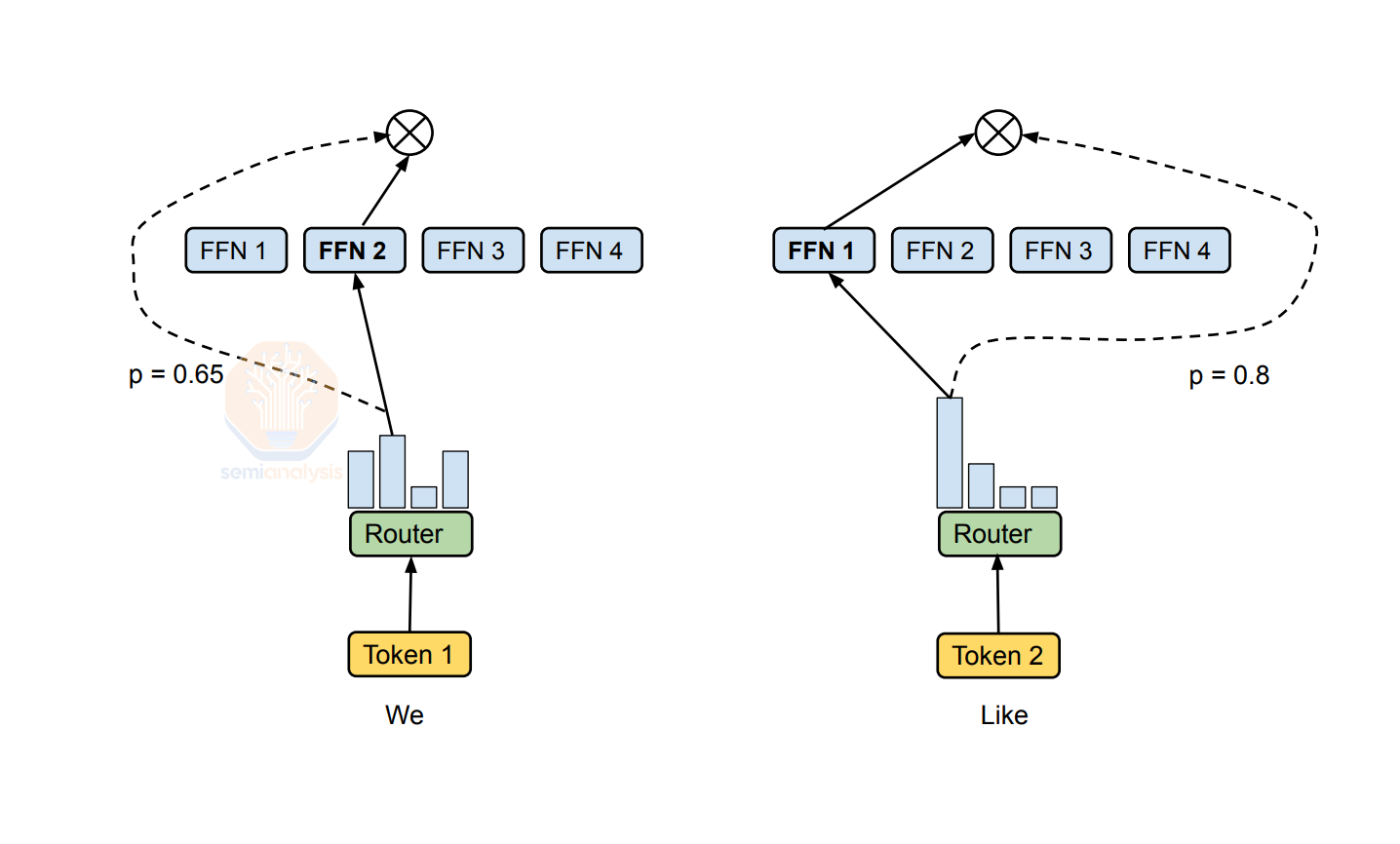
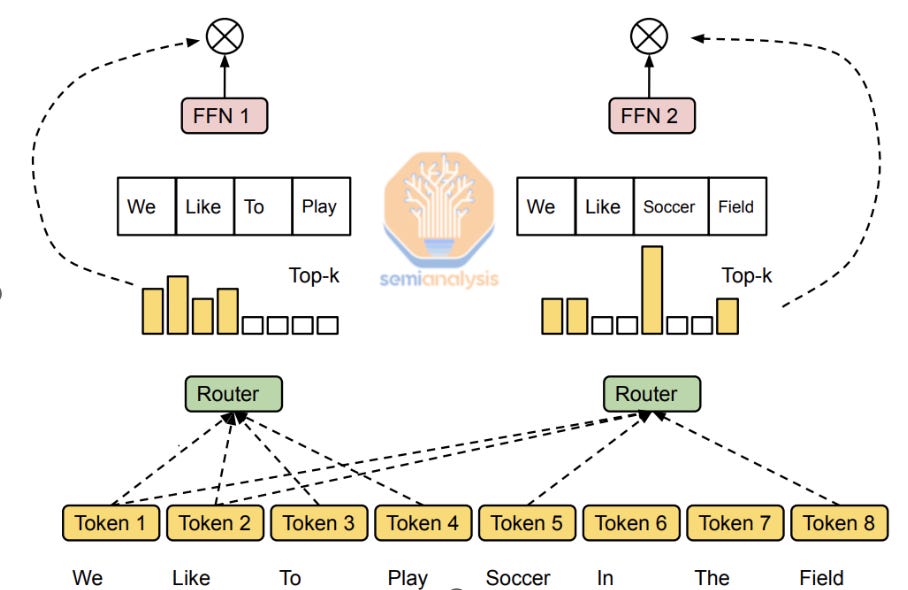
大多数现代LLM使用专家混合架构,其中在每个模型层之间,标记基于路由器被路由到不同的专家。在现代MoE模型中,大多数都使用标记选择路由进行训练,即路由器提供一个形状为T×E的张量(T是总标记数,E是MoE模型中的专家数),并在E维度上运行topK softmax,产生一个T×K张量。这实际上意味着路由器被要求为T个标记中的每一个选择K个最可能的专家,K可以是一个或多个专家。K是研究人员可以调整的超参数。
与标记选择路由直接相比,专家选择路由保证专家以平衡的方式被激活,避免了与不平衡专家相关的性能下降。需要明确的是:路由器在两种情况下都做出选择。在标记选择中,路由器的输入是标记,它选择专家。在专家选择中,路由器的输入是专家,它选择标记。
这平衡了专家训练负载,并提高了分布式硬件的MFU。超大规模网络专为这种并行性而构建,我们在我们的网络模型中广泛讨论了它们。
这种方法的缺点与标记选择架构相反。专家选择路由可能导致某些”流行”标记被多个专家关注。虽然这不会产生标记选择路由中存在的相同训练瓶颈,但它可能导致模型泛化能力下降,因为LLM现在不会对所有标记给予同等关注。此外,大多数EC模型需要用TC训练来完成,以产生有效的LLM。
推理也是EC的一个问题。推理分为两个步骤:Prefill和Decode。在Prefill阶段,用户提示被编码并加载到KVCache中。此步骤受Flops限制。在Decode阶段,模型计算注意力并一次一个标记、一次一个层地运行模型的馈送前向网络。
在这里,专家选择路由遇到了困难,因为专家最初只能从每层1个标记×批处理大小中选择,与训练时相比,每个专家只得到一小组标记(示例训练运行将有8k序列长度×16批处理大小=每通道128k标记)。能够像在训练中那样看到整个序列会破坏现代自回归模型的因果性,因此即使是EC模型也需要EC和TC的混合。
Meta在运行过程中从专家选择切换到标记选择路由,这对于EC模型来说并不罕见。然而,切换导致的性能下降使模型比完全在TC上训练的模型差得多。
数据质量:自作自受
Llama 3 405B是在15T个标记上训练的,我们相信Llama 4 Behemoth需要多得多的标记,数量级大3-4倍。获得足够高质量的数据是一个主要瓶颈,西方超大规模企业无法通过复制其他模型输出的家庭作业来捷径。
在Llama 4 Behemoth之前,Meta一直在使用公共数据(如Common Crawl),但在运行中途切换到他们构建的内部网络爬虫。虽然这通常更好,但也适得其反。团队 struggled to clean and deduplicate the new data stream. 这些流程尚未经过大规模的压力测试。
此外,与包括OpenAI和Deepseek在内的所有其他领先的AI实验室不同,Meta不使用YouTube数据。YouTube讲座转录和其他视频是数据的绝佳来源,公司可能在没有这些数据的情况下难以生产多模态模型。

扩展实验
除了上述技术问题外,Llama 4团队还 struggled to scale research experiments into a full-fledged training run. 有相互竞争的研究方向,缺乏领导力来决定哪个方向是最有成效的前进路径。某些模型架构选择没有适当的消融研究,而是被扔进了模型。这导致了 poorly managed scaling ladders.
作为扩展实验有多困难的例子,让我们看看OpenAI的GPT 4.5训练。OAI的内部代码单仓库对于训练他们的模型非常重要,因为他们需要一个验证数据集来在训练消融时测量困惑度,这个数据集已知未被污染。在扩展GPT 4.5训练实验时,他们看到了模型泛化能力的有希望的发展,只是在运行中期意识到仓库的某些部分是直接从公开可用的数据复制粘贴的。模型不是在泛化,而是在重复记忆训练数据集中的代码!大型预训练运行需要极大的勤奋和准备才能有效执行。
尽管存在所有这些技术问题,但并非全无收获。Meta仍然能够将logits提炼成更小、更高效的预训练Maverick和Scout模型,绕过了较大模型的一些有缺陷的架构选择。蒸馏对于小型模型比强化学习高效得多。也就是说,这些模型仍然受到其来源的限制:它们在其规模上不是最好的。
Meta GenAI 2.0 第二部分:弥补人才差距
随着基础设施改造正在进行并吸收了技术经验教训,Meta的GenAI 2.0战略现在转向超级智能的下一个要素:人才。
Mark Zuckerberg理解与领先AI实验室的人才差距,并亲自接管招聘工作。他的使命是组建一个规模小但人才极度密集的团队,轻松提供数千万美元的签约奖金。目标是创造”飞轮效应”:顶级研究人员加入冒险,为项目带来信誉和动力。最近的高调招聘已经显示出效果,包括:
- Nat Friedman,前GitHub CEO
- Alex Wang,前Scale AI CEO
- Daniel Gross,他是SSI(Ilya Sutskever的初创公司)的CEO和联合创始人
招聘宣传很有力:每个研究人员无与伦比的计算能力,构建最佳开源模型系列的机会,以及超过20亿日活跃用户的访问权限。通常为4年2亿至3亿美元的报价也加强了这一宣传。因此,Meta已经从OpenAI、Anthropic和其他公司获得了出色的人才。
并购、Scale AI等
据报道,Zuckerberg曾向Thinking Machines和SSI提出收购要约,但被拒绝。虽然有些人注意到Zuckerberg”退而求其次”选择了Scale AI,但我们不认为这是事实。正如我们讨论的,Llama 4许多问题的核心是数据问题,而Scale收购直接解决了这一问题。
Alex将带来Scale的许多顶尖工程师,特别是专注于评估的SEAL实验室,这是Meta迫切需要的。SEAL开发了推理模型评估的顶级基准之一HLE(人类最后的考试)。随着Nat Friedman和Daniel Gross加入团队,Meta不仅获得了精英运营商,还获得了AI社区中最多产和最受尊敬的两位投资者。Meta在顶层拥有非常强大的产品人才。
买得越多,省得越多:OBBB版
Zuckerberg couldn’t have picked a better time to start this spending splurge. One Big Beautiful Bill有一些针对超大规模企业的特定税收优惠,可以大幅加速税收激励,以便现在就建设并大规模发展。由联邦政府资助的超级智能是现代的曼哈顿计划。
原文: https://semianalysis.com/2025/07/11/meta-superintelligence-leadership-compute-talent-and-data/
