前沿模型训练已将GPU和AI系统推向极限,使得成本、效率、功耗、每TCO性能和可靠性成为有效训练讨论的核心。Hopper与Blackwell的比较并不如英伟达所宣传的那么简单。
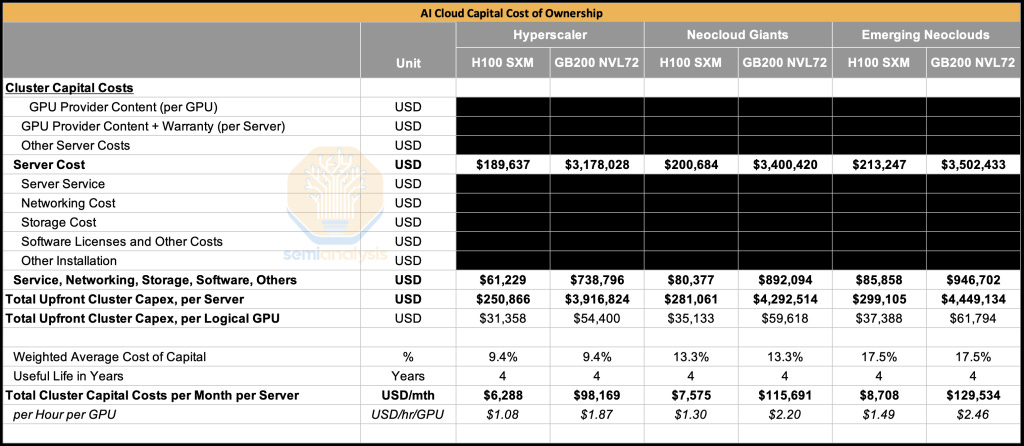
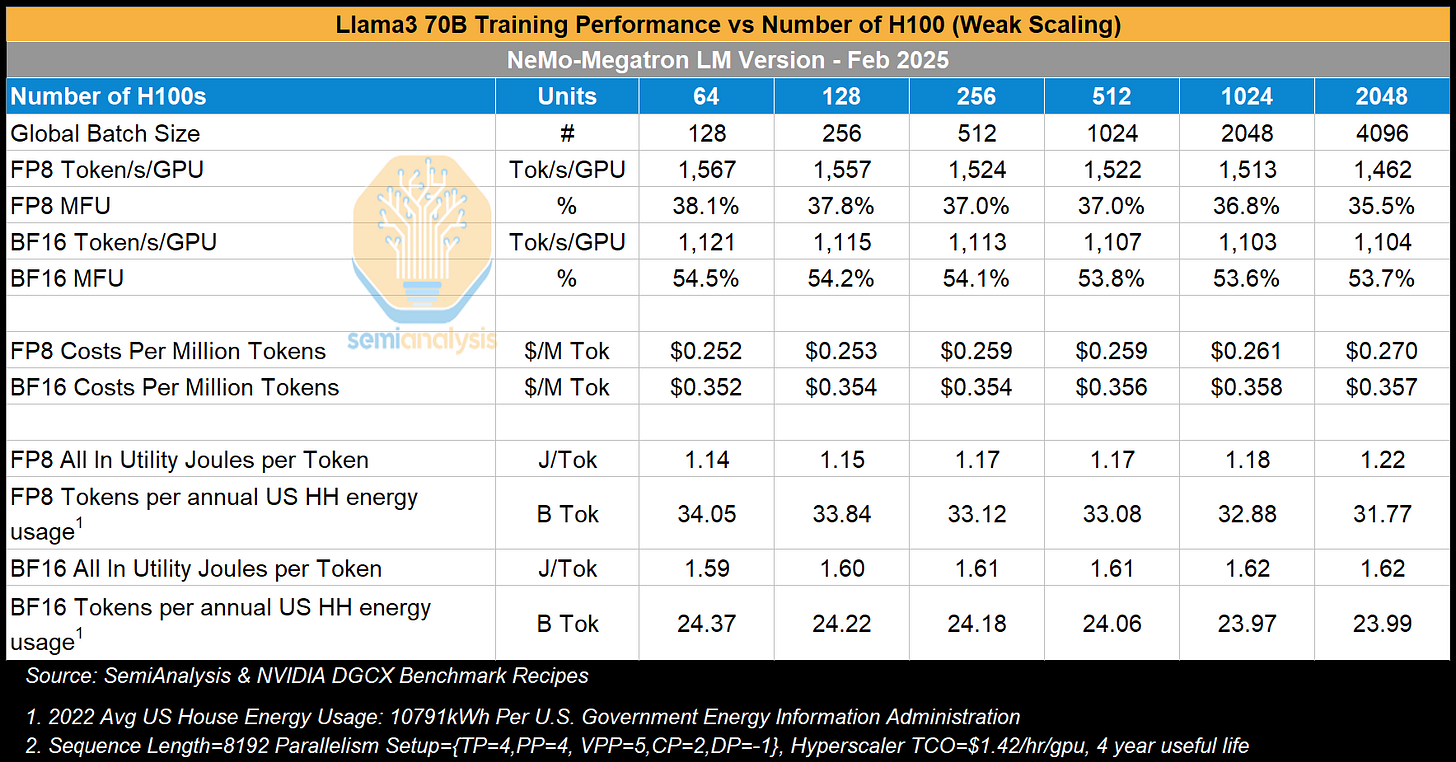
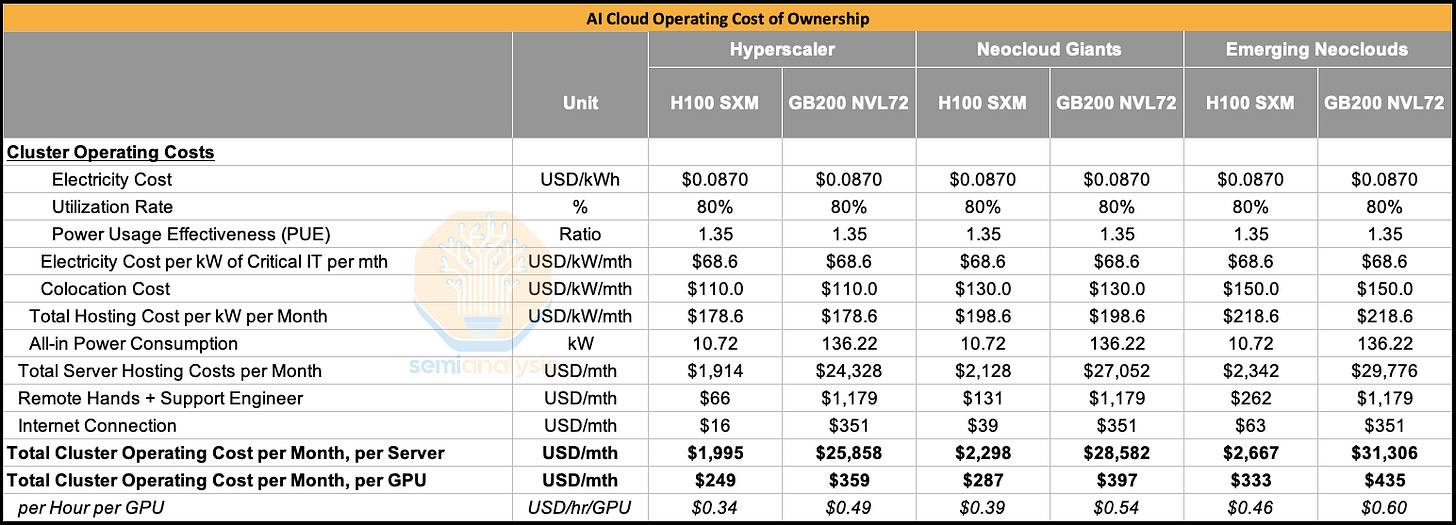
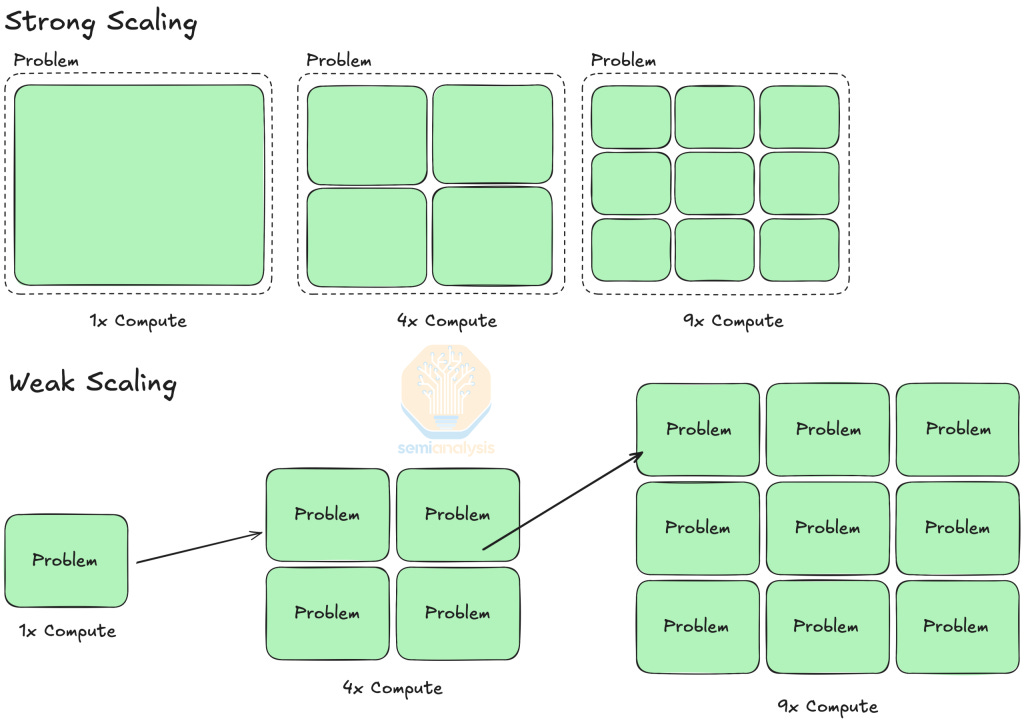
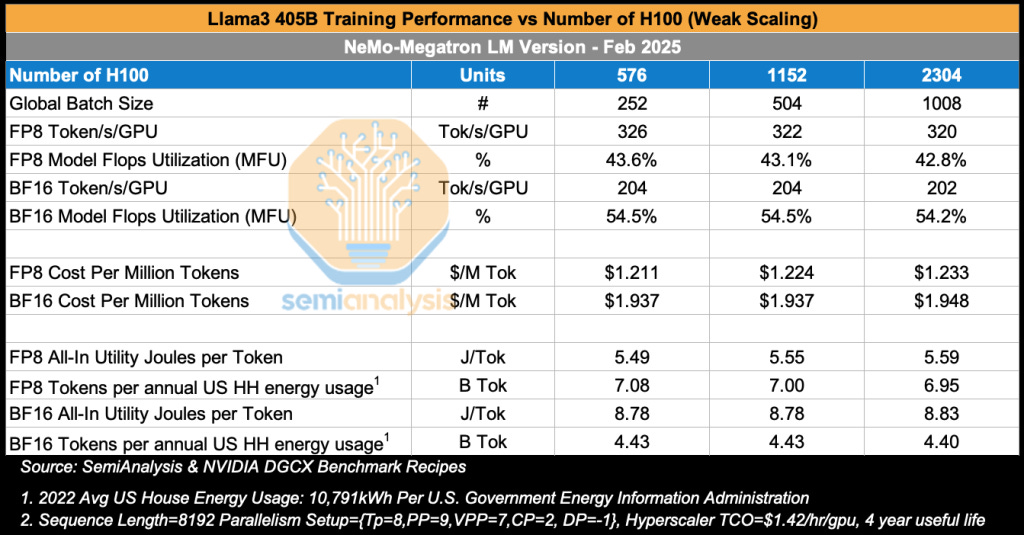
在本报告中,我们将首先展示在2000多块H100 GPU上运行的基准测试结果,分析模型浮点利用率(MFU)、总拥有成本(TCO)和每训练100万代币的成本。我们还将讨论能源使用情况,检查每个训练代币消耗的公用事业焦耳数,并将其与美国家庭年均能源使用量进行比较,从社会背景重新定义能效。我们还将展示当GPU集群从128块H100扩展到2048块H100以及不同版本NVIDIA软件时此分析的结果。
在本报告的后面部分,我们还将分析GB200 NVL72在Llama4 400B MoE和DeepSeek 670B MoE上的基准测试结果,并将这些数据与我们之前H100的结果进行比较。我们将讨论在考虑可靠性问题后,GB200 NVL72的每美元性能优势是否仍然存在。

由于可靠性差和工程时间损失导致的停机是我们将在每TCO性能计算中捕获的主要因素。由于软件持续成熟和可靠性挑战正在解决,目前还没有在GB200 NVL72上进行过大规模训练运行。这意味着英伟达的H100和H200以及谷歌TPU仍然是当今能够成功完成前沿规模训练的唯一GPU。就目前而言,即使是前沿实验室和云服务提供商(CSP)中最先进的运营商也尚未能够在GB200 NVL72上执行大型训练运行。
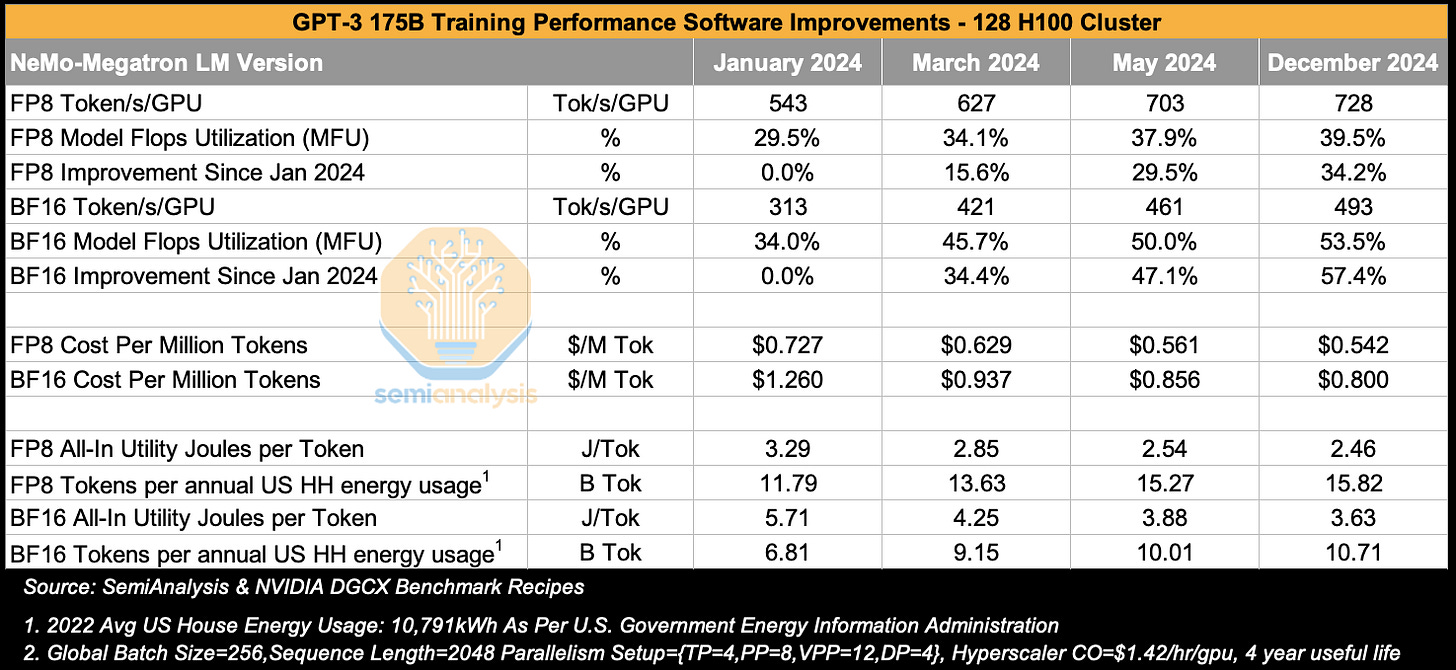
话虽如此,每个新架构自然需要生态系统时间来有效提升软件以利用该架构。GB200 NVL72的推广速度比前代产品略慢,但差距不大,我们有信心在今年年底之前,GB200 NVL72的软件将得到显著改进。结合前沿模型架构在设计时就考虑了更大规模的世界大小,我们预计到今年年底使用GB200 NVL72将获得显著的效率提升。
在可靠性方面,英伟达必须与其合作伙伴更紧密合作以快速解决的重大挑战将继续存在,但我们认为生态系统将迅速调动资源来解决这些可靠性挑战。
原文: https://semianalysis.com/2025/08/20/h100-vs-gb200-nvl72-training-benchmarks/